Notes on Bun's Rust Rewrite and Review Debt
I read through Bun PR #30412 and the surrounding threads. The useful story is not Rust beating Zig. It is what happens when Claude Code makes the first draft of a serious runtime migration cheap, and the proof work becomes the expensive part.
I read Bun PR #30412 because the summaries were already getting too clean.
Usually a bad sign.
The PR is titled "Rewrite Bun in Rust". It was merged on May 14, 2026. GitHub shows 1,009,257 additions, 4,024 deletions, and 2,188 changed files. The source branch was claude/phase-a-port.
This is exactly the kind of event that makes the internet stupid for a day.
One camp wants the headline to be: Rust killed Zig.
Another camp wants it to be: Claude rewrote Bun.
Both are too small.
The version I care about is more annoying, and probably more useful:
Bun merged a very large Rust port, apparently keeping much of the old architecture, with Claude Code traces around the work, using the existing test suite as the main proof harness, while leaving behind a lot of code that humans now need to understand, audit, clean up, and maintain.
Less fun than a language war.
Closer to what happened.
The short version
Here is the part I think is safe to say today.
On May 14, 2026, Bun merged PR #30412 into main.
The PR says the Rust version passes Bun's pre-existing test suite on all platforms. It says the rewrite fixes several memory leaks and flaky tests. It says the binary gets smaller by around 3 MB to 8 MB. It says benchmarks are neutral to faster.
It also says something easy to miss: the codebase is largely the same architecture and the same data structures.
That changes the reading.
This does not look like a clean redesign of Bun. It looks more like a huge port that keeps the product shape and moves a large part of the implementation into Rust so the compiler can help with memory bugs.
Jarred also says there is more optimization and cleanup work to do before this lands outside canary.
You can try the Rust canary with:
bun upgrade --canary
So, no, I would not write "Bun is done rewriting itself in Rust".
I would write: Bun merged the Rust rewrite into main, canary users can try it, and now the hard part becomes proving and cleaning the result.
Already big enough.
Why I am writing this as notes
I do not use Bun every day, so I am not going to pretend I have production scars from running it at scale.
What I can do is read the public material carefully.
The public material is already more interesting than the hot takes:
| Source | What it gives us |
|---|---|
| PR #30412 | The merged change, the stated motivation, the canary note, and the cleanup caveat |
| Jarred's thread mirror | The 99.8 percent Linux test milestone and the "not just Claude" pushback |
| The Register timeline | The earlier moment when this still looked like an experiment |
| Anthropic's Bun announcement | The Claude Code business context |
| HN thread | The questions engineers immediately started asking |
I want the post to stay inside that box.
If a claim cannot be tied to one of those things, I either mark it as a question or leave it out.
That makes the article slower.
Good.
This is a runtime migration, not a launch tweet.
The timeline moved fast
The speed is the first strange thing.
Not because fast means bad. Sometimes fast work is just fast work.
It is strange because the public state changed very quickly.
On December 3, 2025, Anthropic announced it had acquired Bun. From that moment, any big Bun engineering story was going to be read through the Claude Code lens.
On May 5, 2026, The Register covered Jarred Sumner posting a Zig to Rust porting guide. The public state at that point was still uncertain. The article frames it as speculation and notes that Jarred had said there was no commitment to rewriting, only curiosity about seeing a working version.
That detail matters.
Early skepticism was reasonable.
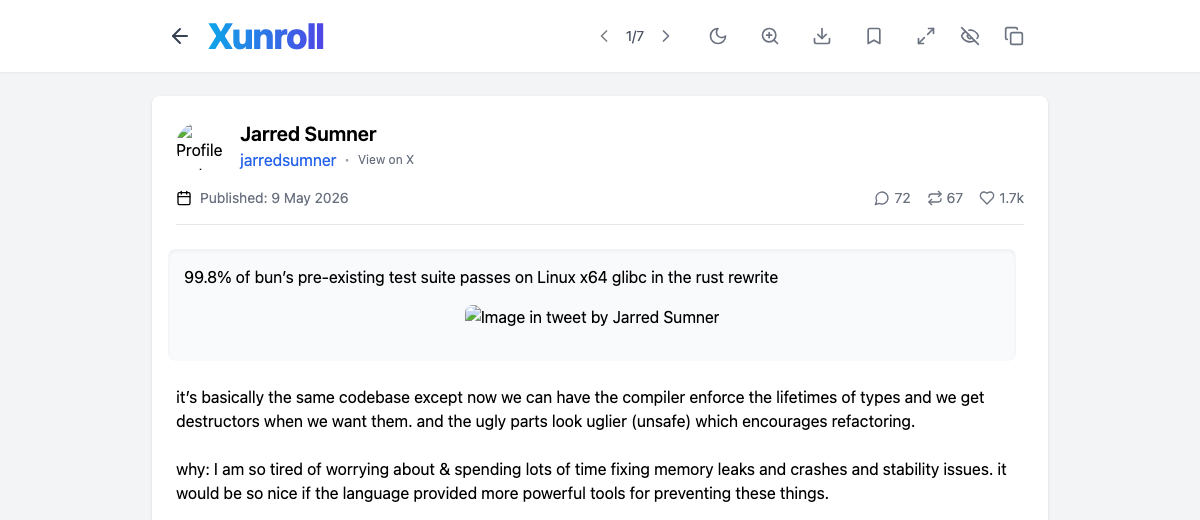
On May 9, Jarred posted that the Rust rewrite passed 99.8 percent of Bun's pre-existing test suite on Linux x64 glibc.
On May 14, PR #30412 was merged.
So the public progression was:
| Date | Public state |
|---|---|
| Dec 3, 2025 | Anthropic announces it is acquiring Bun |
| May 5, 2026 | Zig to Rust porting guide gets public attention, still framed as experimental |
| May 9, 2026 | Jarred says 99.8 percent of existing tests pass on Linux x64 glibc |
| May 14, 2026 | PR #30412, "Rewrite Bun in Rust", is merged |
I keep returning to that part.
The branch went from "maybe an experiment" to "merged into main" in public view in about a week.
I am not saying that means the internal work only took a week. Public timelines are not engineering timelines. There may have been preparation, prior tooling, older experiments, and private context we cannot see.
But the visible transition still matters, because everyone else will copy the visible story, not the invisible one.
And the visible story says something like this:
With strong tests, an existing implementation, and agentic tooling, a serious first draft can arrive before the surrounding social process has caught up.
This is the part that feels new.
The PR body is more practical than the discourse
The PR body does not read like a Rust victory speech.
The core reason given is boring in the best way: memory bugs cost too much time.
Bun is not only a JavaScript runtime. It is also a package manager, bundler, test runner, transpiler, shell, and a lot of native integration around JavaScriptCore, file systems, subprocesses, sockets, allocators, and operating system behavior.
In a codebase like that, memory bugs are not theoretical.
They become:
- random crashes
- flaky tests
- leaks that appear under real workloads
- platform differences that only show up under pressure
- debugging sessions that eat days
- fixes that make one subsystem better and another one weird
Jarred's framing is that Rust gives Bun compiler assistance around a class of problems that had become expensive.
Better reason than "Rust is popular".
It is also narrower.
Rust does not make a runtime correct. Rust does not remove every memory problem. Rust does not turn FFI code into a monastery. Rust does not audit unsafe blocks for you.
But Rust can force some things into the type system that would otherwise live in discipline, convention, and reviewer memory.
In a large runtime, that matters.
When Jarred says the ugly parts become uglier because they show up as unsafe, that is the argument I find strongest.
Not that unsafe disappears.
That unsafe becomes visible.
Visible ugly is easier to budget for than invisible ugly.
The "same architecture" detail is doing a lot of work
I keep thinking about this sentence from the PR body: same architecture, same data structures.
That caveat is doing a lot of work.
If you preserve architecture and data structures, you also preserve a lot of assumptions.
Some of those assumptions are good. Bun is already a working runtime. A faithful port can keep behavior stable and avoid turning a language migration into a product redesign.
Some assumptions are dangerous. If a part of the old code depended on object lifetime discipline, arena behavior, pointer identity, mutation order, or "this global is fine because we only touch it here", then the Rust port has to express that somehow.
There are a few ways that can happen:
- the code becomes clean Rust and the ownership model captures the rule
- the code uses an arena or index based design
- the code uses reference counting or interior mutability
- the code goes through FFI or raw pointers
- the code lands in
unsafe - the code compiles, passes tests, and still has a maintenance trap hiding inside it
That last case is the one nobody can measure from a screenshot.
So I dislike the phrase "rewritten in Rust" when people use it as a final verdict.
"Rewritten in Rust" is a starting point.
The interesting question is what shape the Rust has.
Is it idiomatic Rust?
Is it faithful port Rust?
Is it "C with lifetimes where the compiler forced us" Rust?
Is it temporary Rust that will be cleaned up later?
Probably all of those, in different places.
Normal for a huge migration. Also exactly why follow-up work matters more than the merge announcement.
What changed in the repository
The public numbers are huge.
GitHub shows:
| PR metric | Value |
|---|---|
| Additions | 1,009,257 |
| Deletions | 4,024 |
| Changed files | 2,188 |
| Source branch | claude/phase-a-port |
| Target branch | main |
GitHub's PR page also shows the merge coming from claude/phase-a-port.
I pulled the file list through the GitHub API while researching this. The top file extensions looked like this:
| Extension | Changed files |
|---|---|
.rs | 1,438 |
.zig | 309 |
.ts | 132 |
.toml | 115 |
.js | 57 |
And the changed paths were concentrated here:
| Path | Changed files |
|---|---|
src | 2,026 |
scripts | 59 |
.claude | 53 |
test | 28 |
Do not turn the 1,009,257 additions into "one million hand-written lines".
That is how bad blog posts are born.
Large PR accounting can include generated files, lockfiles, mechanical output, rewritten modules, deleted and recreated files, and GitHub quirks. The paginated file endpoint I checked did not line up perfectly with the top-level addition count, which is another reason to be careful.
But the shape is still useful.
There are many Rust files. There are still Zig files. There are build changes. There are .claude workflow files. This was not only a normal feature PR that happened to be large.
It looks like an organized migration.
It also looks like a migration with a visible agent workflow around it.
Enough to discuss.
It is not enough to pretend we know exactly who wrote what.
Rust is now larger, but "Rust only" is wrong
I also checked GitHub language data after the merge.
The snapshot I captured showed this:
| Language | GitHub Linguist bytes |
|---|---|
| Rust | 40,527,293 |
| Zig | 28,131,614 |
| C++ | 11,474,094 |
| TypeScript | 4,418,623 |
| C | 1,489,737 |
| JavaScript | 656,738 |
| Shell | 138,172 |
| Python | 113,632 |
GitHub Linguist bytes are not architecture.
They do not tell you which files are build-relevant, which are transitional, which are references for the port, and which will disappear later.
Still, they are enough to reject one lazy sentence.
Bun is not "Rust only" today.
Rust is the largest language category in the repository by bytes in that snapshot. Zig is still very present.
So the better wording is:
Bun merged a Rust rewrite that makes Rust the largest language category, while the repository still contains a large amount of Zig and other native code.
That sentence is ugly.
It is also more accurate.
"No async Rust" is a big clue
One line in the PR body deserves its own section:
No async rust.
That line is doing more work than it looks.
If you hear "Rust rewrite" and imagine Bun becoming a normal Rust service using the usual async ecosystem, that is probably the wrong picture.
Bun already has its own runtime architecture. It embeds JavaScriptCore. It has event loop behavior, subprocess handling, filesystem behavior, bundling, package resolution, HTTP, test execution, transpilation, and other pieces that do not become simple because the implementation language changes.
"No async Rust" suggests the migration did not mean adopting Rust's common async application style.
It suggests something closer to:
- keep the runtime architecture
- keep the low level control
- keep the existing data structure shape where possible
- use Rust to make lifetime and destructor rules more explicit
- expose memory risk through
unsafewhere the compiler cannot prove enough
None of this is easier.
It may actually be harder than writing a new Rust project from scratch, because you are not designing from a blank page.
You are translating a living thing.
And living things have weird corners.
The Claude part is real, but easy to overstate
The branch name was claude/phase-a-port.
The file list included .claude workflows.
Anthropic acquired Bun.
So yes, Claude Code is part of the story.
But I do not like the sentence "Claude rewrote Bun".
It sounds bold and explains almost nothing.
There are several different claims people blur together:
| Claim | Can we say it? |
|---|---|
| The branch had Claude in the name | Yes |
The repo had .claude workflow files | Yes |
| Anthropic owns Bun | Yes |
| Claude Code was heavily involved | Very likely, but the exact process still needs Jarred's writeup |
| Claude alone rewrote Bun | No public evidence for that exact claim |
| Humans only rubber-stamped the result | No public evidence for that exact claim |
Jarred himself pushed back on the "just ask Claude" framing in the public thread.
That does not mean the AI part is small.
It means the AI part is process-shaped, not magic-shaped.
The Register described an earlier porting guide with phases. Phase A was about capturing logic even if the Rust did not compile yet. Phase B was about compiling crate by crate.
That sounds much closer to a migration workflow than a single prompt.
That distinction matters because engineers can learn from workflows.
Nobody can learn from mythology.
The useful unit is not a prompt
I do not think the useful lesson is "write a better prompt".
For this kind of migration, the useful unit seems to be a loop:
- Pick a subsystem.
- Translate enough structure to preserve intent.
- Compile.
- Fix compiler errors.
- Run tests.
- Compare behavior.
- Repeat until the failures are smaller.
- Human-review the weird parts.
- Push the ugly parts into explicit follow-up work.
Not glamorous.
It is also where agents become useful.
A model can generate code, but the repo has to provide resistance. The compiler resists. Tests resist. CI resists. Benchmarks resist. Sanitizers resist. Reviewers resist. Production users resist last, which is the expensive place to learn.
The more resistance you have before production, the more useful the agent becomes.
The less resistance you have, the more the agent becomes a confident text generator with a build step attached.
That difference matters.
The test suite is the main character
Everyone wants to talk about Claude.
I keep thinking about the test suite.
On May 9, Jarred said the Rust rewrite passed 99.8 percent of Bun's pre-existing tests on Linux x64 glibc.
The merged PR later says the test suite passes on all platforms.
Those are different claims at different points in time, and they should not be merged into one fuzzy sentence.
The May 9 claim is the public milestone.
The May 14 PR claim is the merge claim.
Without that test suite, this rewrite would be almost impossible to evaluate from the outside.
A runtime has too many behaviors to eyeball.
You need tests for:
- JavaScript execution
- Node compatibility
- package manager behavior
- bundling behavior
- filesystem behavior
- subprocess behavior
- HTTP behavior
- transpilation behavior
- test runner behavior
- platform behavior
- bugs fixed years ago that nobody remembers until they break again
The test suite is not proof of correctness.
It is proof that a known set of behaviors survived.
Still a lot.
For AI-assisted migrations, I think this is the most transferable lesson:
Do not start with the agent.
Start with the harness.
If the harness is bad, the agent will just produce more code than you can trust.
If the harness is good, the agent has a wall to hit.
That wall is the product.
What passing tests does not prove
Passing tests is evidence.
It is not absolution.
There are many things the public test pass does not prove:
| Concern | Why tests may miss it |
|---|---|
| Memory safety | Rust only proves what stays inside safe Rust, and FFI or unsafe code needs separate care |
| Performance cliffs | A benchmark can look fine while one real workload gets worse |
| Platform behavior | Linux success does not always predict macOS or Windows bugs |
| Maintainer understanding | Tests can pass while the implementation is hard to reason about |
| Security boundaries | A behavior test is not the same as an audit |
| Long tail compatibility | Real projects always find combinations the suite did not cover |
| Build and tooling friction | Code can run and still be painful for contributors |
I am not arguing against tests.
It is the opposite.
The stronger the tests, the more honest you can be about what they do not cover.
Bun's test suite seems to have done real work here. That should be credited. The rewrite did not become plausible because a model generated a lot of files. It became plausible because there was a way to measure whether the files still behaved like Bun.
Different kind of achievement.
It was built before the rewrite.
The scary part is review debt
I keep using the phrase review debt because technical debt is not specific enough.
Technical debt is code you know is messy.
Review debt is code that exists faster than the team can truly absorb it.
That can happen without AI. A human can dump a huge PR too.
Agents make it easier because they reduce the cost of producing the first draft.
Review debt shows up as questions like:
- Which parts were translated mechanically?
- Which parts were redesigned?
- Which Rust abstractions are permanent?
- Which ones are scaffolding?
- Where is
unsafeused because Rust cannot express the old shape cleanly? - Where is
unsafeused because the migration needed to move fast? - Which old Zig assumptions survived under new names?
- Which tests were added only after the port broke something?
- Which parts of the codebase only one person understands?
If you do not answer those questions, the code may still work.
For a while.
But the next maintainer pays interest.
They pay it when a bug lands in a Rust module that looks generated.
They pay it when a platform bug appears and nobody knows whether the old Zig behavior was intentionally preserved.
They pay it when the right fix is not obvious because the ownership model is a translation of old lifetime habits, not a design.
That debt is what I care about.
Not because Bun cannot pay it.
Bun probably has more reason than most projects to pay it.
But the debt exists the moment a diff this large lands.
Unsafe is not bad. Invisible unsafe is bad.
I am not going to publish an unsafe block count here because I have not verified it against the merged tree myself.
There are community counts floating around. They may be right. They may be stale. I do not want this article to become another place where an unverified number becomes a fact.
The more important point is simpler.
Unsafe Rust is not automatically bad.
Every serious systems project has boundaries the compiler cannot fully understand. FFI is full of those boundaries. Runtimes are full of those boundaries. Performance-sensitive code sometimes has those boundaries.
The question is not "is there unsafe?".
The questions are:
- Is the unsafe localized?
- Is each unsafe block documented?
- Is there a safe abstraction above it?
- Is the invariant small enough to check?
- Is there test or fuzz coverage around it?
- Are reviewers able to reason about it without reading half the runtime?
- Does the unsafe exist because the system needs it, or because the port needed a shortcut?
That last one is the hard one.
Agentic migrations can produce working unsafe code.
They can also produce unsafe code that encodes old assumptions without anyone having a fresh conversation about whether those assumptions are still good.
So visible ugly is only step one.
Visible ugly still has to be audited.
A faithful port can be the right move
I do not want this to sound like I think faithful ports are bad.
For a runtime, a faithful port may be the only sane way to start.
If you change the language, architecture, and behavior all at once, you lose the ability to know which change caused the bug.
Keeping the architecture close to the old one gives the team a comparison point.
It lets the test suite act like a contract.
It gives users a chance of getting the same Bun with fewer memory bugs, rather than a new runtime wearing the same name.
Good reason to avoid redesigning everything at once.
The tradeoff is that you inherit old shapes.
So the correct rhythm might be:
- Port faithfully.
- Pass tests.
- Ship canary.
- Audit unsafe.
- Clean up mechanical Rust.
- Refactor subsystem by subsystem.
- Delete old transitional shapes once the team understands the new code.
If that is the plan, I like it.
If the plan is "merged means done", I do not.
The PR body says cleanup is coming, so I am assuming the first plan until proven otherwise.
The language-war reading wastes the best lesson
Bun was a visible Zig success story.
So yes, this move has symbolic weight.
I get why Zig people are annoyed.
I get why Rust people are smug.
I also think both reactions miss the useful part.
The PR does not say "Zig is bad".
It says memory leaks, crashes, flaky tests, and stability work were expensive, and Rust gives the team compiler-assisted tools for a class of bugs.
Practical claim.
You can believe Zig is a good language and still believe Bun had reached a point where Rust's compiler model was attractive.
You can believe Rust is the right move and still worry about a huge AI-assisted port.
You can like Claude Code and still think a million-line diff needs serious human ownership.
You can hate AI slop and still admit that a strong compiler plus strong tests makes some migrations newly possible.
All of those can be true.
Which is why the language-war version is too cheap.
It gives people a team.
It removes the work.
The AI angle is not about intelligence. It is about cost.
Before agents, a rewrite like this had a natural brake on it.
The draft cost was high.
You had to spend months writing enough code to know whether the idea was viable. That cost forced planning, staffing, buy-in, and a lot of internal arguing.
Agents change the cost curve.
They make the draft cheaper.
Not the finished system.
The draft.
That distinction is the whole article.
If the draft gets cheap, teams can attempt migrations that used to be too expensive to even test. Exciting.
If the draft gets cheap, teams can also create code faster than they can review, explain, and own. Dangerous.
Both come from the same change.
The bottleneck moves.
It moves from typing code to proving code.
Or, more honestly, from producing code to accepting responsibility for code.
Bun matters beyond Bun for that reason.
It is a public example of a serious codebase hitting this new cost model.
What I would audit next
If I were following this as a maintainer, I would want boring artifacts.
Boring artifacts are underrated.
I would want a migration map:
| Artifact | Why I want it |
|---|---|
| Subsystem port map | Shows which parts were translated, redesigned, or still transitional |
| Unsafe audit | Shows where Rust cannot prove the invariants |
| FFI boundary notes | JavaScriptCore and platform APIs need explicit care |
| Benchmark matrix | Prevents "neutral to faster" from hiding workload-specific regressions |
| Memory report | Shows whether the rewrite actually improves leaks and peak usage |
| Canary bug tracker | Separates known issues from surprise regressions |
| Contributor guide | Helps new contributors understand the Rust shape |
| Cleanup plan | Prevents the first working version from becoming permanent by accident |
I would also want a list of code that is intentionally not idiomatic yet.
That sounds weird, but it is useful.
During a migration, some ugly code is strategic. You keep it ugly because the first goal is behavior parity.
The problem is when strategic ugliness loses its label.
Six months later, nobody remembers whether a strange abstraction is there because it was the correct design or because it was what made the port compile on Tuesday night.
Write it down now.
Future maintainers will bless you in silence.
What I want from Jarred's promised blog post
Jarred said a detailed blog post is coming.
I hope it is not only benchmark graphs.
I want the uncomfortable version.
I want to know:
- what the first generated Rust looked like
- how many phases the workflow actually had
- what humans planned before Claude touched the code
- where the model was useful
- where the model produced junk
- what the compiler caught that tests missed
- what tests caught that Rust missed
- how many failures were platform-specific
- where unsafe concentrated
- how much code was rewritten by hand after generation
- what review process made the PR mergeable
- what follow-up PRs are already planned
- what they would never do this way again
That post would be genuinely useful.
Not because everyone should copy Bun.
Because most teams should not copy Bun.
But everyone building with agents needs more real process writeups and fewer miracle stories.
What this means for normal teams
Most teams should not look at Bun and think:
"We should ask Claude to rewrite our backend in Rust."
Wrong lesson.
The lesson is closer to:
If you want agents to touch serious code, build the thing that tells them no.
That thing can be:
- a strong test suite
- fast local checks
- compiler strictness
- typed boundaries
- snapshot tests
- fuzzers
- property tests
- benchmark gates
- fixture corpora
- replayable production cases
- code owners who actually review the risky areas
Without those, agents make mess faster.
With those, agents can become part of a serious migration loop.
Bun had a big advantage here: an existing product with a large behavior surface and a test suite that could act as a target.
If your codebase has weak tests and unclear ownership, an agentic rewrite will not reveal the future.
It will reveal your lack of brakes.
What this means for Bun users
If you use Bun in production, I would not panic because of the Rust rewrite.
I would also not blindly jump onto canary because the PR is exciting.
The boring advice is correct:
- read the release notes
- test your own workload
- watch canary issues
- care about platform-specific bugs
- measure cold start, install speed, memory, and test runner behavior in your own repo
- wait for non-canary if Bun is critical in your stack
The PR says users should file issues if they run into problems.
That tells you what phase this is.
It is public enough to test.
It is not finished enough to treat as settled.
Fine.
Canary exists for this.
What this means for Zig
I do not think this PR should be read as "Zig failed".
Bun got very far with Zig.
That matters.
It also seems true that Bun hit pain around memory bugs, crashes, and stability work, and Rust offered a different tradeoff.
Both can be true.
There is also a social layer here. Zig has a strict policy against AI generated issues, pull requests, and tracker comments. Bun is now owned by Anthropic, and this PR has Claude workflow traces all over it.
People will connect those dots.
Some of that conversation will be useful.
Most of it will probably be tribal.
The technical question is still narrower:
For Bun's maintainers, at Bun's current size, with Bun's bug profile and Anthropic's tooling, did Rust plus Claude Code plus the existing test suite produce a better maintenance path than staying mostly in Zig?
That is the question I care about.
We do not know the final answer yet.
The merge is one data point.
The next six months are the real data.
The article I do not want to write
I do not want to write:
"Bun proves AI can rewrite million-line codebases."
That sentence is almost useful, then it ruins itself.
Bun proves something narrower:
A serious team can use agentic tooling to produce a large port quickly when the target behavior is already encoded in tests and the maintainers are willing to keep pushing through compile failures, test failures, platform issues, cleanup, review, and canary feedback.
Less catchy.
It is also the thing you can actually use.
The difference between those two sentences is the difference between a demo and engineering.
My current take
I think this PR is worth taking seriously.
Not as a victory lap for Rust.
Not as a funeral for Zig.
Not as proof that Claude Code can replace maintainers.
I take it seriously because it shows the next bottleneck.
The code can arrive fast.
The proof cannot be skipped.
The test suite matters more than the prompt. The compiler matters more than the headline. The cleanup plan matters more than the merge screenshot. The humans still matter because they inherit the result.
That is what I want to remember after the discourse burns out.
Bun did not just "become Rust".
Bun took on a Rust-first port with a lot of AI-assisted process visible around it. The merge answers one question: can they get it into main with tests passing?
Now the better questions start:
- Can they reduce the unsafe and transitional code into something maintainable?
- Can they keep performance flat or better across real workloads?
- Can canary users shake out the long tail without too much pain?
- Can contributors understand the new codebase?
- Can the team publish enough process detail for the rest of us to learn something?
That is where the story becomes useful.
Quick answers for searchers
Did Bun rewrite from Zig to Rust?
Yes. Bun merged PR #30412, titled "Rewrite Bun in Rust", on May 14, 2026. The safest wording is that Bun merged a large Rust port into main, not that every part of Bun is now only Rust.
Is Bun fully Rust now?
No. Rust became the largest GitHub language category by bytes in the snapshot I checked, but the repository still contained a large amount of Zig, plus C++, TypeScript, C, JavaScript, and other files.
Did Claude Code rewrite Bun?
Claude Code was clearly part of the public story. The branch was named claude/phase-a-port, and .claude workflows were present. The exact split between agent work and human work should wait for Jarred's process writeup.
Why did Bun move toward Rust?
The PR points to memory bugs, crashes, flaky tests, stability work, and the desire for compiler assistance around those problems.
Did the Rust rewrite pass Bun's tests?
Jarred first posted that 99.8 percent of Bun's existing tests passed on Linux x64 glibc. The merged PR later says the pre-existing test suite passes on all platforms.
Does passing tests mean the rewrite is safe?
No. Passing tests is strong evidence for tested behavior. It does not prove memory safety, security, maintainability, or performance across every real workload.
Should other teams copy this?
Only if they also copy the boring parts: tests, CI, benchmarks, ownership, review, canary feedback, and a cleanup plan. Copying only the "ask an agent to port the code" part is how you make a large mess quickly.
Links
- GitHub PR: Rewrite Bun in Rust #30412
- Jarred Sumner thread mirror: 99.8 percent test compatibility
- Hacker News discussion: Bun's experimental Rust rewrite hits 99.8 percent test compatibility
- Earlier HN thread: Zig to Rust porting guide
- Anthropic announcement: Anthropic acquires Bun
- The Register timeline: Bun posts Rust porting guide